Conducting a Business Impact Analysis
It is 2020. Here is what we have learned: giant murder hornets are coming, we all love...
Responding to a critical cyber incident can be an incredibly stressful and intense time. While nothing can fully alleviate the pressure of dealing with an attack, understanding these key tips from incident response experts will give your team advantages when defending your organization. This blog highlights the biggest lessons everyone should learn when it comes to responding to cybersecurity incidents.
When an organization is under attack, every second matters. There are a few reasons why teams may take too long to react. The most common is that they don’t understand the severity of the situation they find themselves in, and that lack of awareness leads to a lack of urgency.
One way to stay ahead in the fight for time is with deception technology, like our Dragnet. Dragnet is a lightweight software token that drastically reduces the time between intrusion and notification so that you can act in a more timely fashion. It acts as a loaded mousetrap, luring bad actors to files. When these files are accessed, your team is notified immediately. That way hackers can’t snoop about your network undetected.
Attacks tend to hit at the most inopportune times: holidays, weekends, and in the middle of the night. Since most incident response teams are significantly understaffed, this can understandably lead to a “we’ll get to that tomorrow” attitude. But unfortunately, tomorrow may be too late to do something to minimize the impact of the attack. Overwhelmed teams are also more likely to react slowly to indicators of attack because they suffer from alert fatigue, which means signals get lost in the noise. Even when a case is initially opened, it may not be correctly prioritized due to a lack of visibility and context. This costs time, and time is not on a defender ’s side when it comes to incident response.
Even in situations where the security team is aware that they are under attack and something needs to be done immediately, they may not have the experience to know what to do next, which also makes them slow to respond. The best way to combat this is by planning for incidents in advance.
When it comes to incident response it’s not enough to only to treat the symptoms. It’s important to treat the disease as well.
When a threat is detected, the first thing to do is triage the immediate attack. This could mean cleaning up a ransomware executable or a banking Trojan or blocking the exfiltration of data. However, often teams will stop the initial attack but not realize they haven’t really solved the root cause.
Successfully removing malware and clearing an alert doesn’t mean the attacker has been ejected from the environment. It’s also possible that what was detected was only a test run by the attacker to see what defenses they’re up against. If the attacker still has access, they’ll likely strike again, but more destructively.
Incident response teams need to ensure they address the root cause of the original incident they mitigated. Does the attacker still have a foothold in the environment? Are they planning to launch a second wave? Incident response operators who have remediated thousands of attacks know when and where to investigate deeper. They look for anything else attackers are doing, have done, or might be planning to do in the network – and neutralize that, too.
For example, in one instance, Sophos incident response specialists were able to thwart an attack that lasted nine days and saw three separate attempts by the attackers to hit an organization with ransomware.
Since they were not yet a Sophos MDR customer, the Sophos Rapid Response team was first engaged. In the first wave of the attack (which was ultimately blocked by the organization’s endpoint protection solution) attackers targeted 700 computers with Maze ransomware and were making a ransom demand of US$15 million. Realizing that they were under attack, the target’s security team engaged the advanced incident response skills of the Sophos Managed Detection and Response (MDR) team.
The Sophos incident response specialists quickly identified the compromised admin account, identified and removed several malicious files, and blocked attacker commands and C2 (command and control) communications. The Sophos MDR team was then able to defend against two additional waves of attacks by the adversary. If the attackers had succeeded and the victim had paid, this could have been one of the most expensive ransomware payments to date.
In another example, the Sophos MDR team responded to a potential ransomware threat but quickly realized there was no evidence of ransomware. At this point, some teams might have closed the case and moved on to other work. However, the Sophos MDR team continued investigating and uncovered a historic banking trojan. Fortunately for this customer, the threat was no longer active, but it serves as an example of why it’s important to look beyond the initial symptoms in order to determine the full root cause, as it could be an indicator of a broader attack.
While navigating an attack, nothing makes defending an organization more difficult than flying blind. It’s important to have access to the right high-quality data, which makes it possible to accurately identify potential indicators of attack and determine root cause.
Effective teams collect the right data to see the signals, can separate the signals from the noise, and know which signals are the most important to prioritize.
Limited visibility into an environment is a sure-fire way to miss attacks. Over the years, many big-data tools have been brought to market to try and solve this specific challenge. Some rely on event-centric data like log events, others utilize threat-centric data, and others rely on a hybrid approach. Either way, the goal is the same: collect enough data to generate meaningful insights for investigating and responding to attacks that would otherwise have been missed.
Collecting the right high-quality data from a wide variety of sources ensures complete visibility into an attacker’s tools, tactics, and procedures (TTPs). Otherwise, it’s likely only a portion of the attack will be seen.
Fearing they won’t have the data they need to get the full picture of an attack, some organizations (and the security tools they rely upon) collect everything. However, they’re not making it easier to find a needle in a haystack; they’re making it harder by piling on more hay than is necessary. This not only adds to the cost of data collection and storage, but it also creates a lot of noise, which leads to alert fatigue and time wasted chasing false positives.
There’s a saying among threat detection and response professionals: “Content is king, but context is queen.” Both are necessary to run an effective incident response program. Applying meaningful metadata associated to signals allows analysts to determine if such signals are malicious or benign.
One of the most critical components of effective threat detection and response is prioritizing the signals that matter the most. The best way to pinpoint the alerts that matter the most is with a combination of context provided by security tools (i.e. endpoint detection and response solutions), artificial intelligence, threat intelligence, and the knowledge base of the human operator.
Context helps pinpoint where a signal originated, the current stage of the attack, related events, and the potential impact to the business.

No organization wants to deal with breach attempts. However, there’s no substitute for experience when comes to responding to incidents. This means that the IT and security teams often tasked with high-pressure incident response are thrown into situations that they simply don’t have the skills to deal with; situations that often have a massive impact on the business.
The lack of skilled resources to investigate and respond to incidents is one of the biggest problems facing the cybersecurity industry today. This problem is so widespread that according to ESG Research2, “34% say their biggest challenge is that they lack skilled resources to investigate a cybersecurity incident involving an endpoint to determine root cause and the attack chain.”
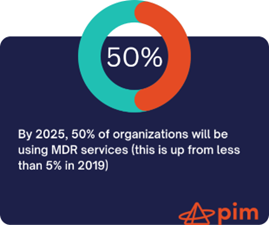
This dilemma has given way to a new alternative: managed security services. Specifically, managed detection and response (MDR) services. MDR services are outsourced security operations delivered by a team of specialists, and act as an extension of a customer’s security team. These services combine human-led investigations, threat hunting, real-time monitoring, and incident response with a technology stack to gather and analyze intelligence. According to Gartner, “by 2025 50% of organizations will be using MDR services”3, signaling a trend that organizations are realizing they will need help to run a complete security operations and incident response program.
For organizations that have not employed an MDR service and are responding to an active attack, incident response specialist services are an excellent option. Incident responders are brought in when the security team is overwhelmed and needs outside experts to triage the attack and ensure the adversary has been neutralized.
Even organizations that have a team of skilled security analysts can benefit from collaborating with an incident response service to shore up gaps in coverage (i.e. nights, weekends, holidays) and specialized roles that are needed when responding to incidents.